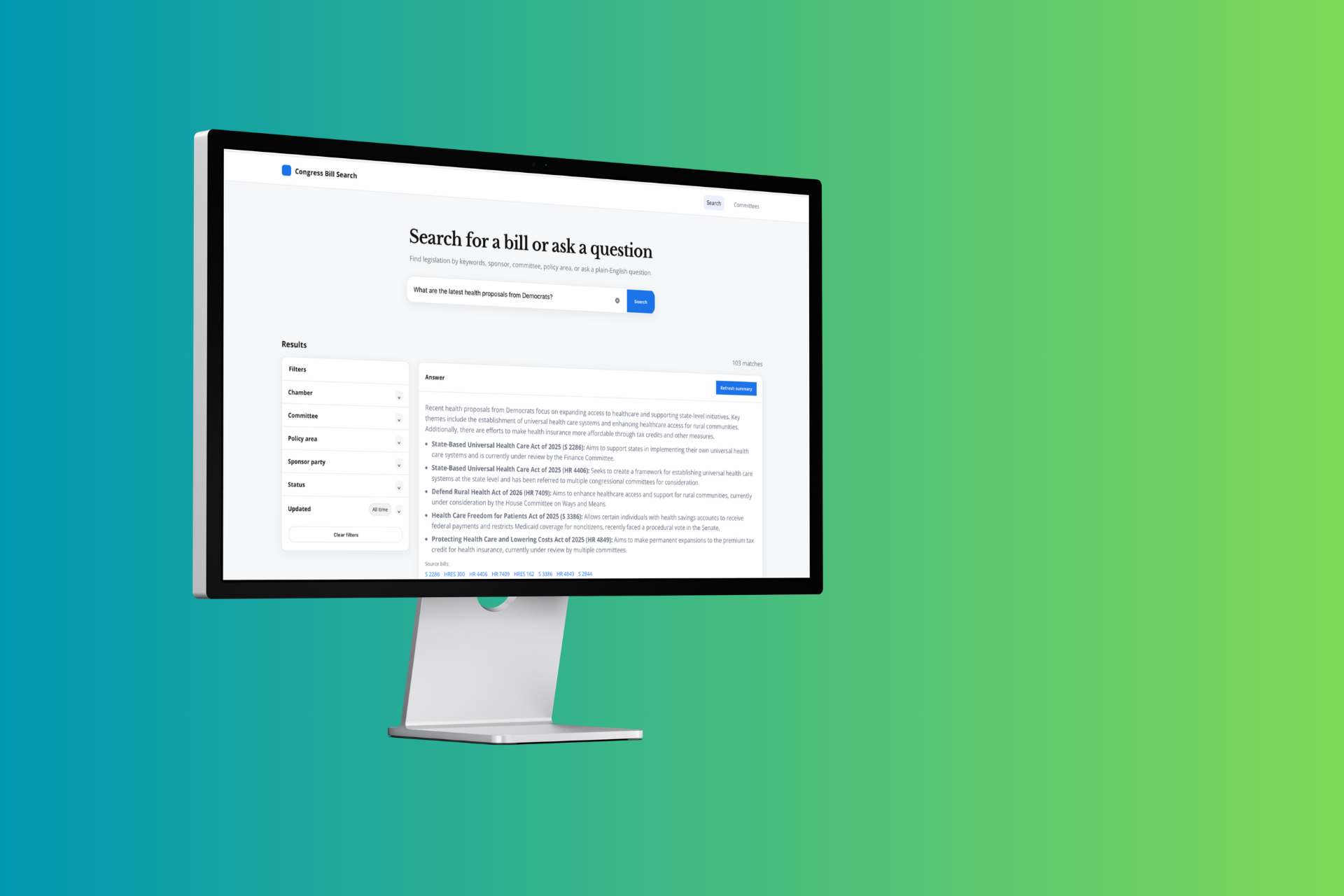
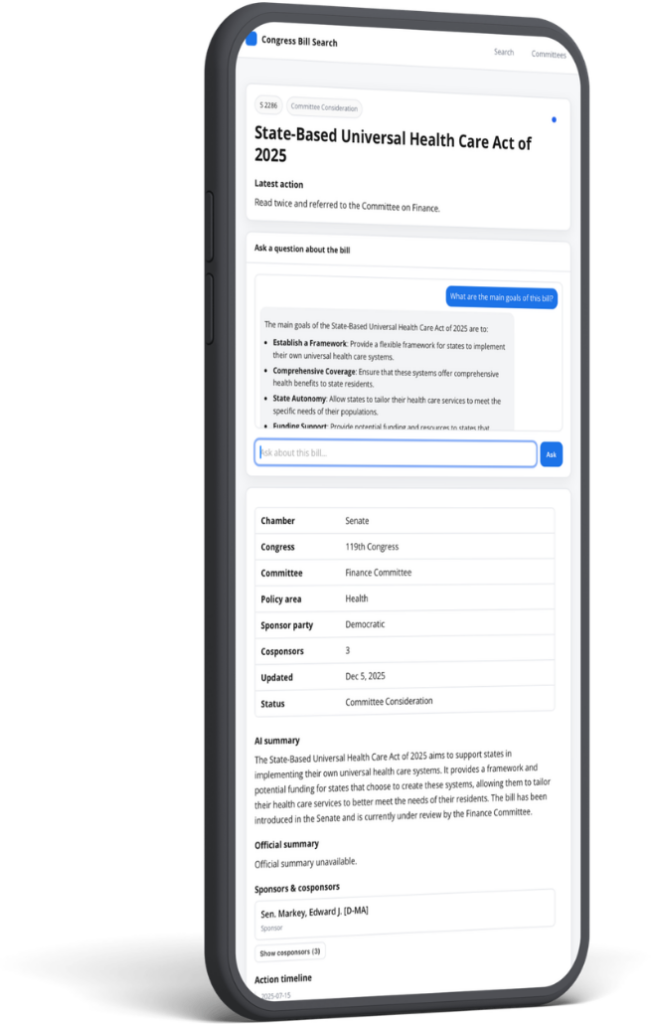
This project turns bill data from the U.S. Congress into a fast, filterable research tool by combining Congress.gov ingestion, Typesense hybrid search, and vector AI retrieval. It layers an AI assistant on top of the search system to answer plain-English questions with clickable source bills. The same stack also powers individual bill pages, where an AI chat can drill into bill text, actions, and metadata.